3.0版本上线!大改版,简约同时更实用!建议一定更新!
我一直很喜欢一种网页风格:没有排版,也没有华丽的装饰,各种文字信息以较高密度呈现在观看者眼前的风格。后来我逐渐意识到,这种风格十分偏向于千禧年前后,匠人手制网页的模样。
在我把Typecho更新之后,曾经的主题便不兼容了。也是在这时候,我发现Typecho自己的主题挺有我说的那种味道的,于是打算直接用默认主题就得了。但渐渐的,我发现默认主题还是多多少少有些缺失的,比如首页直接把文章全文按顺序排列,浏览文章十分不便。所以,我最终决定把官方这个主题打磨一下,让它成为我心目中最理想的,最千禧年风格主题。现在,它来了。


一、特性及优势
基于官方主题,原汁原味的简约,完全区分文章与独立页面这两个Typecho的文章形式。在此基础上有着更多优势:
- 紧凑的自适应布局,高信息密度、清晰的观感
- 亮暗模式,轻点按钮即可实现
- 可选置顶文章,公开事项不必担心被新发表内容淹没了
- 可选在首页展开最新发布的文章,主次区分更明显。若开启,首页即是文章页
- 可选展示指定分类下的最近发布文章列表,条理更清晰,博客主题更凸显
- 可选展示随机文章,引流更全面
- 可选展示联系方式,全面宣传不再困难
- 所有可以看到的图形元素均已font-awesome字符化,包括搜索栏右边的放大镜按钮,加载快人一步
- 搜索、归档、分类文章界面半隐效果,增加点击概率
- 分类、标签同级展示,另请参阅更直接
- 自动划分章节导航,长文定位更方便
- 图片点击放大,展示更多细节
- 可选友链区域,邻居联系更紧密
- 可选自定义页脚,灵活定义页面功能
- 文章编辑页可输入原文链接,同公众号“阅读原文”效果
二、安装、设置
2.1版本后,插件TePostViews作为主题推荐插件会在后台弹窗提示。推荐安装激活以获得更完全的体验。
直接前往gitee下载最新发行版,解压到你的Typecho文件夹/usr/theme/中将文件夹重命名为Millennium-style,然后在Typecho后台启用即可。
每次推出新版本时,typecho后台—控制台—外观—设置外观会弹出提示。此时再次前往前面的网页下载最近发行版,解压覆盖即可。
当前,如果你熟悉git操作的话,也可以直接克隆这个工程的master分支。这样每次发出新版本的时候,只需同步一次即可。
现在,可以切换到主题的设置界面进行自定义了。下面详细介绍每一个设置项。
1、首页展示最新文章
若开启,则首页会全文显示最新发布的文章。
2、最近回复
若开启,则侧栏会展示网站内除文章作者外的最近回复内容。
3、分类列表
若开启,则侧栏会展示网站的分类结构。
4、文章归档
若开启,则页脚会展示文章归档板块。
5、随机文章
若开启,则侧栏会展示随机文章板块。
这五个选项对应的效果如图所示。

在选项下面,是一系列自定义功能,相关说明如下。
6、置顶文章
在这里输入文章的cid使其在首页置顶显示,留空则不启用。多篇置顶可以连续输入,通过英文逗号分隔。置顶的文章可以在首页显示标题及一部分文章内容。
获取cid默认情况下是简单的,只需查看文章链接中的数字即可。
如果你有自定义文章slug的习惯,那么也许需要到Typecho控制台-管理-文章下,找到对应的文章后,查看编辑文章的链接,其最后会有?cid=字段,等号后面的数字便是文章的cid了。
使用效果如下图。

注意:推荐输入不超过3篇置顶文章,以获得最佳展示效果。
7、指定分类的最近发布
在这里输入分类的slug,使首页直接展示这些分类下的文章列表,留空则不启用。多个分类可以连续输入,通过英文逗号分割。这些列表将只显示标题而不再显示正文预览。
获取slug也是简单的,直接进入Typecho控制台-管理-分类中查看缩略名一列即可。
使用效果如下图。
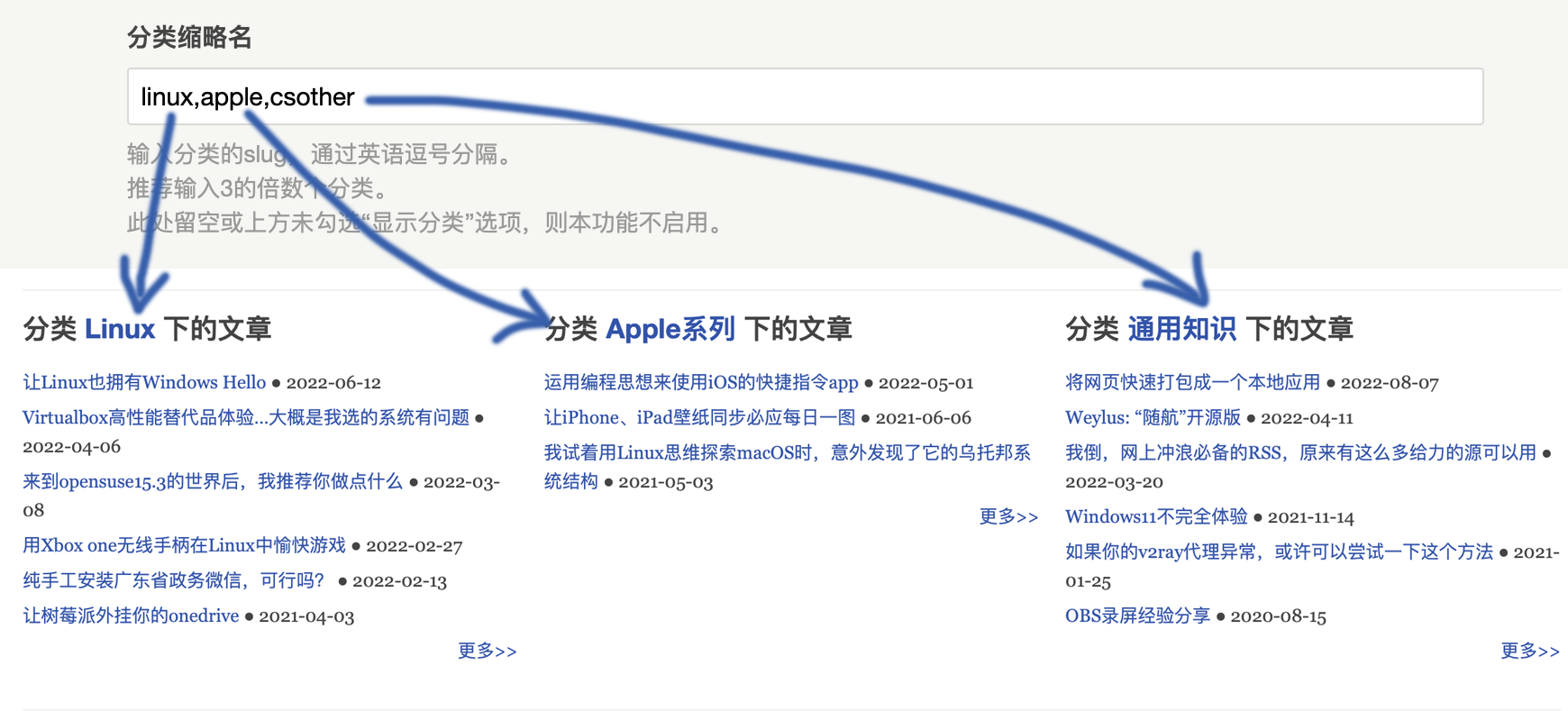
注意:推荐输入3的倍数个分类,以获得最佳展示效果。
8、联系我
在这里输入内容以启用“联系我”板块。这里输入的内容结构是所有设置项目中最繁琐的:一行一个社交平台信息,按照社交平台名,链接,图标,用户名的形式输入即可(中间通过英文逗号分隔)。
- 社交平台名:鼠标放到社交按钮上会浮现出来的名字
- 链接:如微博、其他平台的主页等,会有对应的超链接地址。有则复制,没有则输
# - 图标:关联font-awesome。直接输入font-awesome的图标样式即可;若没有则留空(不过font-awesome那么多图标,总会有一个是比较沾边的)
- 用户名:展示在图标旁的名字。当然也可以使用社交平台的名字而不用用户名
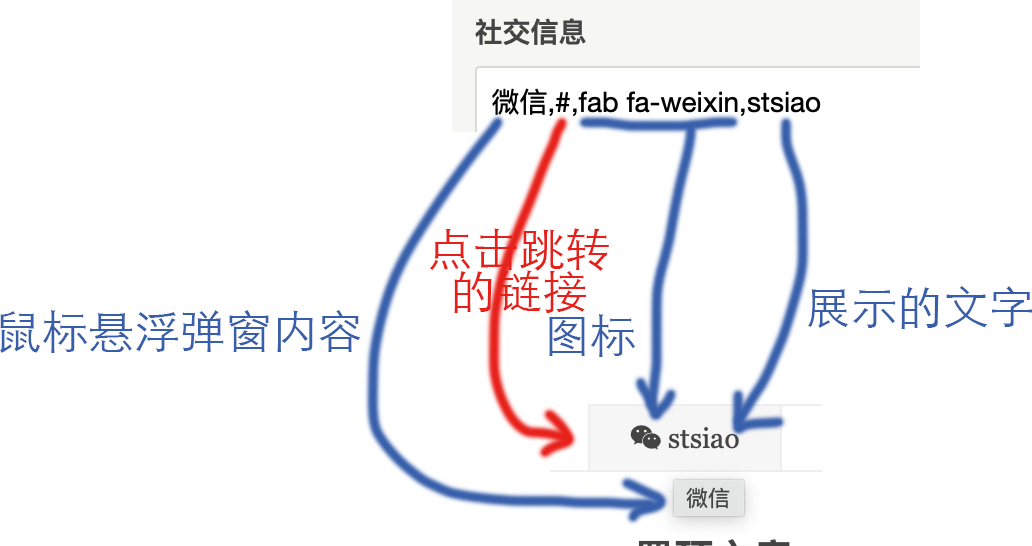
下面举几个例子。
1、微信(有用户名、有图标、无链接)
微信,#,fab fa-weixin,stsiao
2、Tg(有用户名、有图标、有链接)
telegram,https://t.me/stsiao,fab fa-telegram,@stsiao
3、灵感创造者(我的另一个站点,无用户名,无图标,有链接)
灵感创造者,https://kanban.bwsl.wang,,灵感创造者
对于站内链接,也可以放在这里。比如增加一个本站RSS订阅按钮:
RSS,/feed,fa fa-rss,RSS
使用效果如下图。

对于手机端,此板块会自动调整至页脚展示。

9、随机文章显示数量
当勾选了随机文章功能,那么可以在这里自定义这个模块显示的文章数量。留空则应用默认值8篇。
10、友链
在此处输入内容以启用“友链”板块。内容结构为一行一个,按照名称,地址格式书写。其中:
- 中间为英文逗号
- 逗号前的部分支持HTML语法插入图片等内容
- 逗号后的地址应以http或https开头
使用效果如下图。

11、自定义页脚
在此处输入内容以启用自定义页脚部分。通过HTML语法书写任何内容。可以是展示在页面最下方的文本,也可以是一段CSS样式表,甚至是一段js代码。
最基本的使用效果如下图。

三、编写文章
1、标题导航
主题拥有标题导航功能。编写文章/独立页面时,只需根据需要设置不同等级的标题样式,发布后即可自动划分文章并在侧栏展示,点击便可跳转至文章对应位置。

注意:此模块仅在电脑端展示
2、阅读原文
类似于微信公众号的阅读原文按钮,在编写文章时,将链接填入编辑页面底部的原文链接处,发布后便会自动在文章底部增加此按钮,点击即可跳转。

注意:此功能仅对文章生效,独立页面填写后不做响应。
那么就说到这儿吧,祝使用愉快。